Zero-Copy
By allocating at-most one relatively small block of memory for the KERN_PROCARGS2 sysctl, and then only ever indexing into but never copying out of that buffer even when writing to stdout, getargv does not have to worry about allocator performance.
No backtracking / Single Scan / Linear Time Algorithm
getargv will look at each byte of the procargs buffer no more than once. It does not backtrack, and it does not lookahead. There is no additional time complexity beyond the size of the target process' arguments. getargv eagerly stops when it exhausts the argument count of the target process, and skips bytes intelligently where possible.
- no backtracking
- O(n) time complexity
- zero-copy
- O(1) space complexity
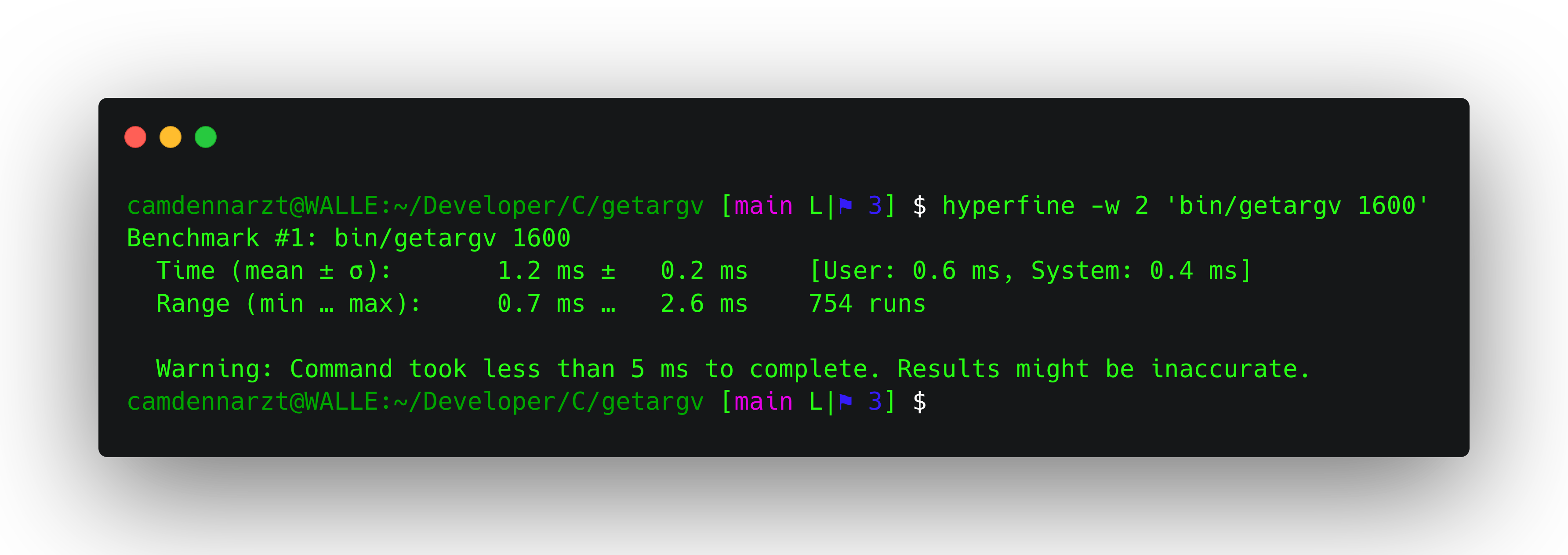
getargvruns in approx 0.6 ㎳ on an M2 MacBook Air as measured byhyperfine- I'm still looking into vectorizing the code, if I can